
The Raft Consensus Protocol
Published:
Raft is a protocol that solves the distributed systems problem of consensus. Specifically, Raft allows a network of machines to agree on the entries in an append-only log. When an entry is committed to the log on one machine, the protocol gaurantees no other machine will ever commit a different entry at the same index.
Assumptions
As with all distributed system protocols, Raft makes assumptions about its adversaries and failed nodes. Raft is a crash fault tolerant (CFT) protocol, which means that failed nodes can only fail by suddenly terminating execution. For example, another failure mode is byzantine fault tolerance (BFT). In BFT, nodes can fail by executing arbitrary operations and can even be malicious. Raft, being a CFT protocol, assumes that every node is benign and therefore every node that is still “awake” follows the protocol exactly.
When designing distributed systems, we define the number of nodes needed for correct operation of the protocol in terms of f, the number of expected failed nodes. Under CFT, a system needs a minimum of 2f + 1 nodes to operate correctly. What f is is up to the system maintainers. It is important to note that if the number f is exceeded, assumptions about the correctness of the protocol no longer hold. For example, if we are maintaining a cluster of 5 nodes, the protocol will work as long as no more than 2 nodes fail.
Distributed systems also need to make assumptions about the network. Raft assumes messages can be dropped or arbitrarily delayed, but they cannot be tampered with. The protocol assumes that messages arrive exactly as they were sent by their source. Under other models, messages may be required to be received in order, or at least delivered to the protocol in the order they were sent by the source.
Consensus
Consensus is the process in distributed system of achieving agreement on a fact or set of facts. In the context of Raft, this agreement is on the entries in a log, an append-only list.
Typically, consensus protocols have two sub-protocols: leader election and “normal operation.”
Leader Election
Having a leader allows for easier serialization of log entries, but requires a protocol for electing a new leader on leader failure.
The leader election protocol in raft can be summarized as:
Which node does a simple majority believe has the most up-to-date log?
When a node initiates an election, it tells the other machines its (1) highest index and (2) the term that entered that index. Based on this, peer machines will vote for the candidate if the term is greater than its own, or the terms are equal and the other machine’s log is at least as long.
Log Append
Normal operation is a bit of a misnomer (the whole protocol is normal operation), but refers to the part of the protocol responsible for accepting input from the user and coming to consensus on the input.
In Raft, log append can be summarized as:
For each follower, the leader sends the follower all un-replicated log entries. The follower appends the log entries and responds. The leader sets the commit index to n when a simple majority of the followers have successfully replicated n. The follower sets the commit index to n when they learn the leader has a committed index of n.
Because there are 2f + 1 nodes in the cluster, if a message is replicated by a simple majority, f + 1, the committed entry is gauranteed to be able to survive if f nodes fail. If f nodes that replicated the log entry fail but one survives, it will be able to claim leadership because it has the most up-to-date log. Subsequently, as leader it will be able to replicate that log entry to the surviving followers.
Distributed systems and Go
I’ve implemented the Raft protocol using Go here. Go’s support for concurrency makes it a natural fit for distributed system development. Let’s take a look at how it was done.
Repository organization

cmd/httpraftAn executable that provides a HTTP APIcnetNetworking library for the raft protocolclient.goGo API for raftmessages.goDefinitions of protocol messagesraft.goCore protocolutil.goRandom useful functions
Architecture
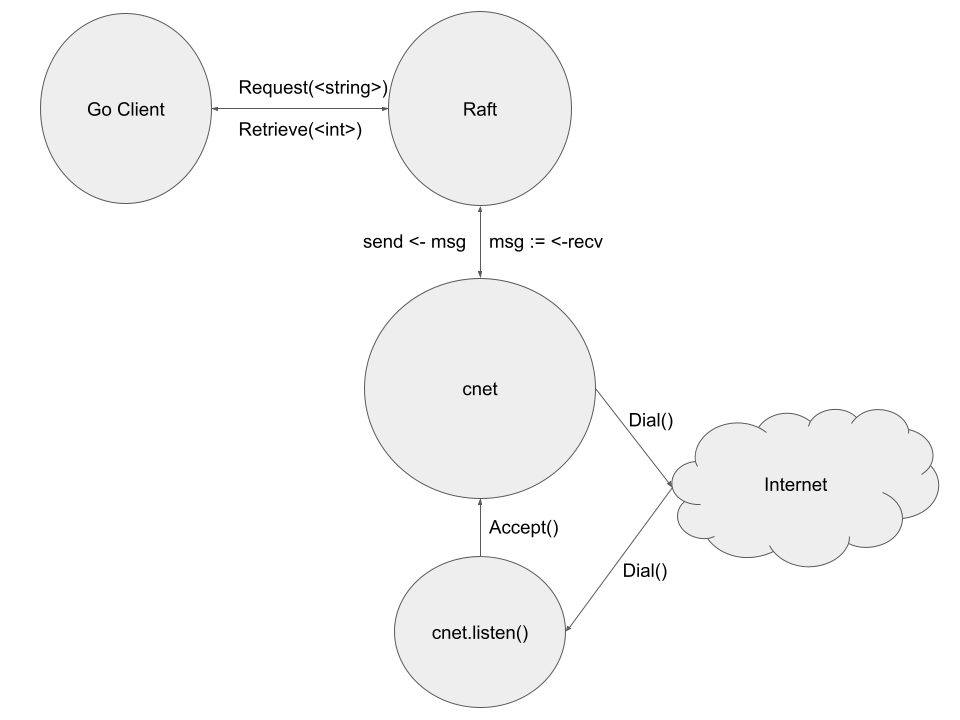
In the above diagram, each circle represents a goroutine. We can see that the Raft module is designed to be run in a separate goroutine from the client program. The API functions in client.go will be run in the same goroutine as the client, and handle communication with the protocol through unexposed input/output channels.
The core Raft logic receives input from the client code and the cnet networking module. It executes logic based on received messages and timeouts, and sends output to cnet. As with the client library and Raft, the Raft logic runs the networking module in a separate goroutine and communicates messages to send and those received by channels.
Finally, the networking library runs two goroutines. The main goroutine executes the send and receive logic while the second listens for incoming connections. When the listening goroutine accepts a connection from a client, the connection is passed to the main cnet goroutine so it can execute the receive logic.
Main loop
The primary execution of the model proceeds as follows.
func (r *Raft) Run() {
send := make(chan cnet.PeerMsg, 100)
recv := make(chan cnet.PeerMsg, 100)
go r.net.Run(send, recv)
//...
for {
//...
var timeout time.Duration
var callback func(chan cnet.PeerMsg)
switch r.role {
// Set timeout and callback based on role
}
select {
// receive client command
case entry := <-r.input:
r.handleInput(entry, send)
// handle append messages
case am := <-appendChan:
r.handleAppendMsg(am, send)
// handle election
case lm := <-leaderChan:
r.handleLeaderMsg(lm, send)
// progress the protocol
case <-time.After(timeout):
callback(send)
}
}
}
The code follows the principals.
- Set a timeout and callback based on the current role.
- Handle received messages from the network.
- Repeat
This formula gaurantees that the protocol will never become ‘stuck’ in a particular state. There is a constant timer ticking that will trigger action in the case of network or peer failure.
cnet
While Go offers networking libraries, we need to implement some niceness that will abstract away the details of connections and sockets so our module can have a simple interface to the network.
Like the main module, the network is run in a goroutine and interacts with its parent through channels. It also runs a child goroutine to listen for incoming connections. In the main loop, it waits on incoming and outgoing messages, and operates on them accordingly.
func (n *Network) Run(send, recv chan PeerMsg) {
connChan := make(chan net.Conn, 100)
go n.listen(connChan)
for {
select {
case conn := <-connChan:
pm, err := recvMsg(conn)
conn.Close()
if err != nil {
fmt.Println(err)
continue
}
recv <- *pm
case pm := <-send:
n.sendMsg(pm)
}
}
}
Notice in the networking module there is no timeout case. The package will hang if there are no incoming items from the channels. If there were some more advanced state or logic that this library needed to do, we could have a ‘tick’ function within the select. However, because this library’s only job is to pass messages to and from the network and raft module, having this Run method hang is fine.
Also pay attention to the error handling. The same approach here is used throught the other functions in the package. In the receive case, we log the error and continue processing. In the send case, we ignore the return value completely. We can do this because the protocol can cope with dropped messages. If a connection to a peer fails for any reason, we recognize that heartbeats are sent out frequently, and process will continue with the next beat.
httpraft
The raft protocol presented in the repository is designed as a Go module to be imported and used by other Go code. The only functions that should have to be called are New(), Run(), Request(), and Retrieve(). However, in order to test the protocol, interface with other languages, and develop other features on top of replication, a standalone binary would be nice. To that end, I implemented httpraft.
httpraft is a binary written in Go that exposes the operations of the log through a HTTP API. I have written a small Postman collection that shows how httpraft may be used by an external, (not-necessarily-golang) client.
Usage
- Download this repo and build
cmd/httpraft - Download the postman repo
- Create a json configuration for the network, like so:
{ "peers": [ "localhost:8000", "localhost:8001", "localhost:8002" ], "apis": [ "localhost:9000", "localhost:9001", "localhost:9002" ] }Call this file
peers.jsonand put it in the working directory where you will runhttpraft. - Run the binary with
./httpraft <id>whereidis the instance of the protocol. - Point the postman collection to any of the endpoints in
apis.
